테이블 자료구조의 이해
자료구조의 '테이블'은 사전구조, 맵(Map) 이라고 불린다.
키(Key)와 값(Value)가 하나의 쌍을 이루고 있다.
| 사번 : Key | 직원 : Value |
| 100 | 박보검 |
| 101 | 송중기 |
| 102 | 남주혁 |
| 103 | 이준기 |
위 테이블에서 사번이 Key가 되고, 직원 이름이 Value가 된다.
위와 같은 데이터를 어떻게 메모리상에서 효율적으로 CRUD할 것인가? => Hash Table!!
해시 함수 (Hash Function)
키(key)를 해쉬(Hash)로 바꿔 메모리를 효율적으로 관리하도록 한다.
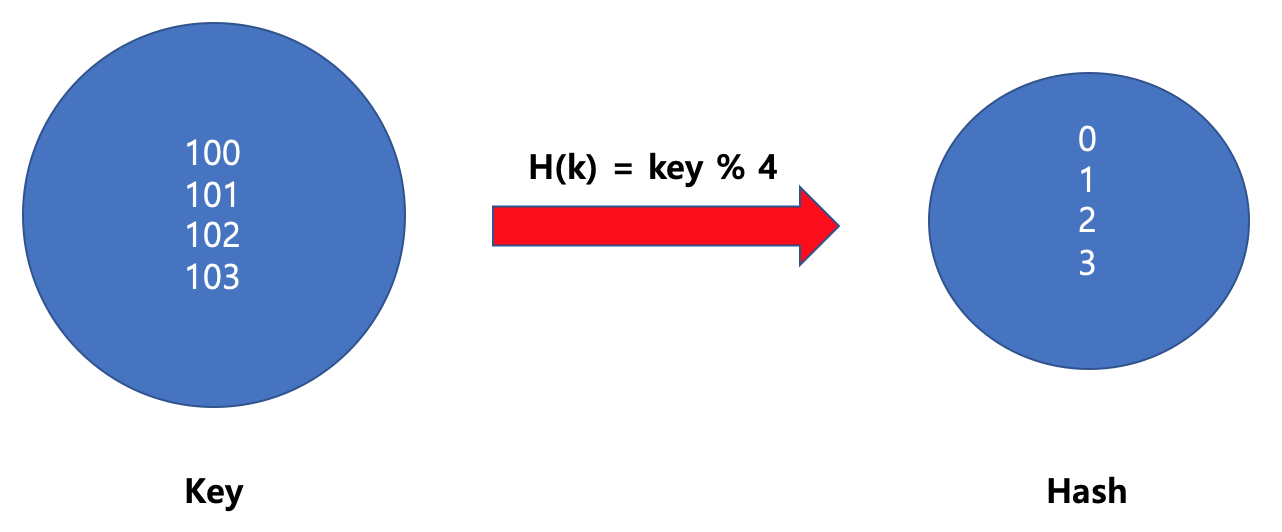
사번 (key)에 대해 hash 함수를 key%4 로 정의하면 길이 4인 배열에 저장할 수 있다.
ex) key 100인 경우, hash 값은 0 (=100%4) 이 되므로 empList[0] = 박보검
하지만 서로 다른 키에 대해 동일한 해시 값이 생성되는 경우 충돌(Collision)이 발생한다.
이 문제를 어떻게 해결할 것인가?
충돌(Collision) 문제의 해결책
1. 열린 어드레싱 방법 (Open Addressing Method)
충돌이 발생했을 때, 그 옆자리가 비었는지 살펴보고, 비었을 경우 그 자리에 대신 저장한다.
- 선형 조사법
k라는 키에서 충돌 발생 시 조사 순서는 f(k)+1 -> f(k)+2 -> f(k)+3 -> f(k)+4...
특정 영역에 데이터가 집중적으로 몰리는 클러스터(Cluster) 현상이 발생하기 쉽다는 단점이 있다.
- 이차 조사법
k라는 키에서 충돌 발생 시 조사 순서는 f(k)+1^2 -> f(k)+2^2 -> f(k)+3^2 -> f(k)+4^2...
선형 조사법에 비해 클러스터 현상이 완화된다.
- 이중 해시 (Double Hash)
이차 조사법도 접근이 진행되는 슬롯을 중심으로 클러스터 현상이 발생할 확률이 여전히 높기 때문에 이를 보완하기 위해
이중 해시 (Double Hash) 를 사용할 수 있다.
1차 해시 함수 : 키를 근거로 저장위치를 결정하기 위한 것
2차 해시 함수 : 충돌 발생 시 몇 칸 뒤를 살필지 결정하기 위한 것
h1(k) = k % 배열의 길이
h2(k) = 1 + (k%c) , c는 배열의 길이보다 작은 소수
(c가 소수인 이유는 클러스터 현상 발생 확률이 현저히 낮다는 통계가 있기 때문이다.)
2. 닫힌 어드레싱 방법 (Closed Addressing Method)
충돌이 발생해도 자신의 자리에 저장한다
- 체이닝 (Chaining) -> 연결 리스트를 이용
하나의 해시 값에 다수의 Slot(Key-Value 데이터)을 둔다.
탐색을 위해서는 동일한 해시값으로 묶여있는 연결된 Slot을 모두 조사해야한다는 불편이 있지만 해시 함수를 잘 정의하여 충돌 확률이 높지 않다면 연결된 Slot의 길이는 부담스러운 정도가 아니다.

위 그림에서 윤아, 유리, 서현, 수영이라는 key는 해시 함수 h(k)를 통해 각각 아래와 같은 결과를 얻는다.
h(윤아) = 2
h(유리) = 1
h(서현) = 2
h(수영) = 4
주목해야할 것은 윤아와 서현의 해시 함수의 결과가 같아 충돌이 발생한다는 사실.
Hash Table의 Chaining 방식은 하나의 Hash 값에 대해 연결 리스트로 다수의 Slot을 두게 된다.
그림에서는 2번 Hash에 윤아 Slot, 서현 Slot을 연결하였다.
Swift 로 구현한 Chaining HashTable
HashTable Class
import Foundation
let MAX_TBL = 100
typealias HashFunction = (Int) -> Int
private var hashFuntion : HashFunction? = nil
struct Slot { // Key-Value 관리
let key : Int
var value : String
init(key: Int, value: String) {
self.key = key
self.value = value
}
}
class Table {
private (set) var hashList = [[Slot]](repeating: [], count: MAX_TBL)
private (set) var hashFunc : HashFunction? = nil
convenience init(hashFunc: @escaping HashFunction) {
self.init()
self.hashFunc = hashFunc
}
public func insert(key: Int, value: String) {
if self.search(key: key) == nil {
let hash = self.hashFunc!(key)
self.hashList[hash].append(Slot.init(key: key, value: value))
} else {
NSLog("Error!! => Duplicated Key")
}
}
public func search(key: Int) -> String? {
let hash = self.hashFunc!(key)
for slot in self.hashList[hash] {
if slot.key == key { return slot.value }
}
return nil
}
public func delete(key: Int) -> String? {
let hash = self.hashFunc!(key)
for i in 0..<self.hashList[hash].count {
let slot = self.hashList[hash][i]
if slot.key == key {
self.hashList[hash].remove(at: i)
return slot.value
}
}
return nil
}
}
구현된 HashTable Test 코드
import Foundation
func myHashFunc(k: Int) -> Int { return k % 100 }
let table : Table = Table.init(hashFunc: myHashFunc)
// 데이터 입력
table.insert(key: 900254, value: "윤아")
table.insert(key: 900139, value: "서현")
table.insert(key: 900827, value: "태연")
// 데이터 탐색
NSLog("value is %@", table.search(key: 900254) ?? "nil")
NSLog("value is %@", table.search(key: 900139) ?? "nil")
NSLog("value is %@", table.search(key: 900827) ?? "nil")
// 데이터 삭제
NSLog("deleted slot's value is %@", table.delete(key: 900254) ?? "nil")
NSLog("deleted slot's value is %@", table.delete(key: 900139) ?? "nil")
NSLog("deleted slot's value is %@", table.delete(key: 900827) ?? "nil")
# 실행 결과

'개발자 공부하기 > 알고리즘' 카테고리의 다른 글
| [C++][백준 2178] 미로탐색 - BFS를 이용한 최단거리 (0) | 2020.10.27 |
|---|---|
| [C++] DFS와 BFS 구현하기 (0) | 2020.10.27 |